Ross, S. M., Kelly, J. J., Sullivan, R. J., Perry, W. J., Mercer, D., Davis, R. M., … & Bristow, V. L. (1996). Stochastic processes (Vol. 2). New York: Wiley.
本文将对 Rank 类指标如 AUC-ROC,设计损失函数,从而实现直接优化。读到这我觉得就像当年学高数一样会有两类反应:这也要证?这也能证?如果你是第一种,那么文章的开头介绍了背景知识,看完你会变成第二种反应的。如果你是第二种,说明你对这个问题已经有了一些研究,那么可以直接从第三部分阅读。本文主要参考 Eban et al. (2016)。
Background
对于分类问题,为了度量一个模型的性能,我们构造出了很多指标,比如准确率、查全率(recall,有些地方翻译为召回率,我觉得还是查全率更直观一些)、\(F_{\beta}\)、ROC曲线等等,根据应用场景的不同,我们使用不同指标进行衡量,比如疾病筛选的时候我们认为把病人诊断为健康人的代价要远远大于把健康人诊断为病人,我们会更加强调查全率,或者我们希望使用\(P@R\),在规定查全率下尽量提高准确率。同时为了比较不同的模型,标量我们可以直接进行数值比较,为了处理如ROC曲线之类的指标,我们又构造了如平衡点(Break-Even Point)、AUC(Area Under Curve)等指标。
过去几十年,大家都是这么做的,并不直接对 AUC 类指标进行优化,默认准确率较高的分类器在AUC等指标上也表现较好,将精力集中在模型结构的创新上。当然也有一些工作,前期的工作主要集中在对函数的近似,也即示性函数近似成可微的函数,比如 Yan et al. (2003),但并没有解决数据之间的全局依赖,从而也就无法应对越来越多的大规模数据的divide and conquer,最近的一些工作如 Narasimhan, H., Kar, P., & Jain, P. (2015, June) 开始在一些特定模型,如广义线性模型上进行优化,下面我们介绍 Google 在最近发表的 Eban et al. (2016) 中的方法,通过分析损失函数的上下界,来对 AUC 构造出可微可分解的损失函数。
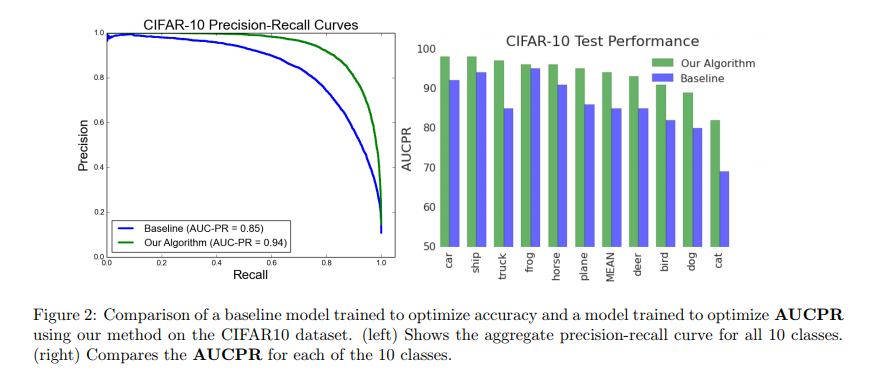
之所以不对结果再详细解释,还有一个原因就是我在kaggle的一个任务上使用上述算法,性能非但没有提升,而是有显著下降。所以文章虽然提出了一个很好的算法,但是在性能的测试上是否有 data snooping?算法的稳定性或者适用条件(比如准确率已经高达95%以上是否还能通过这种优化达到一个提升)我认为是后续的一个研究方向。
Pytext 和 Tensorflow Research 中实现了文中的算法。源码的注释非常完善,我这里就不做解读了,可以直接点开链接阅读。值得注意的是,TensorFlow Research 中对AUCROC的实现并非是按照原文的思路进行的,而是将AUCROC视为我们前面所讲的正确排序的概率,在每个 batch 中使得这个概率最大,以期达到全局最优。
另外,Sanyal et al. (2018) 是非常不错的延伸阅读材料。利用对偶理论提出了新的算法。
Eban, E. E., Schain, M., Mackey, A., Gordon, A., Saurous, R. A., & Elidan, G. (2016). Scalable learning of non-decomposable objectives. arXiv preprint arXiv:1608.04802. Narasimhan, H., Kar, P., & Jain, P. (2015, June). Optimizing non-decomposable performance measures: A tale of two classes. In International Conference on Machine Learning (pp. 199-208). Nedić, A., & Ozdaglar, A. (2009). Subgradient methods for saddle-point problems. Journal of optimization theory and applications, 142(1), 205-228. Sanyal, A., Kumar, P., Kar, P., Chawla, S., & Sebastiani, F. (2018). Optimizing non-decomposable measures with deep networks. Machine Learning, 107(8-10), 1597-1620. Yan, L., Dodier, R. H., Mozer, M., & Wolniewicz, R. H. (2003). Optimizing classifier performance via an approximation to the Wilcoxon-Mann-Whitney statistic. In Proceedings of the 20th International Conference on Machine Learning (ICML-03) (pp. 848-855). 周志华. (2016). 机器学习. 清华大学出版社.